
![]()
27 февраля 2017
Компания «ЦРТ-инновации» представила новый метод выделения контекстов употребления слов из спонтанной речи
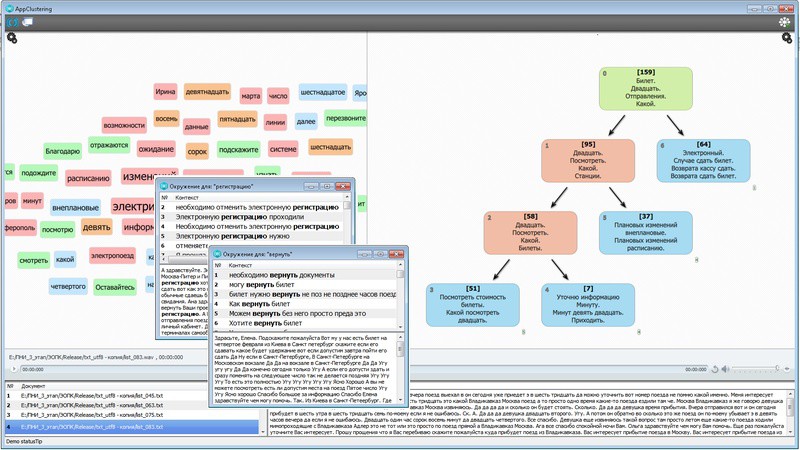
Использоваться новый метод будет в таких инструментах речевой аналитики ЦРТ, как «модуль кластеризации» и «модуль автоматического аннотирования».
Метод основан на технологиях работы с большими данными (big data) и современных методах машинного обучения (machine learning) в сочетании с глубоким лингвистическим и семантическим анализом речи.
Особенно остро проблема «понимания» речи (речевого сообщения и/или большого объема речевых данных) стоит в крупных контакт-центрах, обрабатывающих информацию в постоянном режиме и больших объемах. Именно поэтому основными потенциальными потребителями систем, автоматически выделяющих связные контексты (логические структуры, «ситуации») тех или иных значимых для анализа слов, являются аналитические службы КЦ и служб технической поддержки государственных и коммерческих структур.
Цель выделения контекстов в больших массивах данных - учитывать информацию, непосредственно связанную с целевым словом, и не включать в контекст нерелевантную информацию. Выделение связных контекстов слов в разы упрощает работу аналитиков, позволяя им в автоматическом режиме решать такие задачи, как:
- анализ употребления ключевых слов (людей, организаций, географических объектов) в тексте и/или речи;
- выявление контекстов употребления ключевых (значимых) слов в диалогах;
- составление текстовой аннотации (информативной выжимки) текста и/или речи;
- автоматическое формирование заголовков тематических кластеров и т.п.
Недавние публикации:
Речевая аналитика группы ЦРТ оптимизировала более 80% рутины по аналитике коммуникаций в TruckMotors,
Новость, 11 февраля 2026
Группа ЦРТ разработала для чат-бота метро Москвы Александры голос на основе нейросетей,
Новость, 23 мая 2025
Облачная речевая аналитика группы ЦРТ оптимизировала более 30% времени специалистов FRANK AUTO,
Новость, 02 апреля 2025